



Seedance 2.0是由字节跳动旗下品牌即梦推出的新一代AI视频生成模型,致力于成为面向专业创作的“电影级全流程生成引擎”。其核心在于实现端到端的原生音画同步与多镜头叙事控制,显著提升了AI视频的连贯性、表现力与可用性。
Seedance 2.0 是什么?
Seedance 2.0 是由字节跳动旗下AI创作平台「即梦」推出的新一代AI视频生成大模型。它的定位已超越单纯的“文生视频”工具,旨在成为一个电影级的全流程视频生成与编辑引擎。
Seedance2.0怎么使用
1、在界面中选择创作方式――文生视频(输入文字描述)或图生视频(上传参考图片),根据需求选择合适的工作流。
2、点击上传区域,可批量上传最多 12 个参考文件,包括图片(角色、场景、风格参考)、视频(动作参考)、音频(语音或音乐参考),AI 将自动学习这些素材的特征。
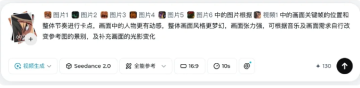
3、如需精确控制镜头,可分别上传第一帧和最后一帧图片,AI 会自动生成中间的过渡动画,实现场景的自然衔接。
4、在文本框中输入视频描述,建议包含场景、动作、氛围、镜头运动等细节,配合参考素材可获得更精准的效果。

5、根据发布平台选择视频比例(横屏 16:9、竖屏 9:16、方形 1:1),选择视觉风格(写实、电影、动漫、赛博朋克等),设置视频时长(5-12 秒)。
6、如需对口型或配音,上传音频文件,系统会自动生成与音频节奏匹配的人物口型和表情。

7、点击生成按钮,等待 AI 处理(速度较上代提升 10 倍以上),预览生成结果,如不满意可调整提示词或参考素材重新生成。
核心特点与突破
原生音画同步与多镜头叙事:
音画对齐:从底层实现视觉与音频并行生成与校准,做到口型、动作与音效的精准匹配。
智能分镜:能将长文本自动拆解为逻辑连贯的多镜头脚本(如全景、中景、特写),并保持角色、场景的高度一致性。
精准控制与高效编辑:
多模态参考:支持通过首尾帧图片、参考视频片段、音频等多种输入,精准控制视频的运镜、动作和氛围。
编辑式工作流:允许用户对生成视频的局部不满意部分进行直接修改或重生成,无需从头开始,极大提升了创作效率和成品率。
强大的场景适配:
在复杂叙事、动作打斗、短剧生成等场景表现突出。
能自动生成或适配背景音乐与音效,支持多语言及指定歌词输入。
关于平台与使用的重要信息
「即梦」与「Seedance」的关系:
即梦 是面向创作者的AI内容创作平台。
Seedance 是该平台自研的核心视频生成模型/技术。您可以理解为:Seedance是引擎,即梦是搭载这款引擎的汽车。
目前应用与内测平台:
模型主要在即梦(Web端及App) 上提供核心功能。
也已面向部分用户在 「豆包」、「小云雀」 等字节系产品中开启内测。
当前使用限制(重要):
暂不支持输入真人图片或视频作为参考(平台正在优化)。
若要在AI视频中使用真人数字分身,在即梦App和豆包App上需通过本人录制形象与声音完成真人校验后方可制作。
核心功能亮点
🌐 多模态参考生成(最多12个文件)
支持同时上传图片、视频、音频作为参考,AI 自动学习并复刻:
画面构图|角色特征|动作风格|镜头语言
无需复杂提示词,精准控制生成效果。
🎞️ 首尾帧控制(关键帧驱动)
上传第一帧与最后一帧,AI 智能生成中间过渡动画,实现:
精准镜头运动|自然场景衔接|可控叙事节奏
🔊 原生音视频同步
人物口型、面部微表情与音频节奏深度对齐,告别“配音感”,真实还原对话与表演情绪。
🎬 多镜头叙事
支持分镜图直接生成完整视频,在多个镜头间保持:
角色一致性|灯光连贯性|美术风格统一
适用于预告片、故事短片等复杂内容创作。
🎵 自动音频生成
内置语音合成(TTS)、背景音乐与环境音效生成能力,实现 音画一体化创作,无需后期配乐。
👤 角色一致性保持
在系列视频中,确保同一角色的面部、服装、发型、表情高度一致,支撑连续剧情与品牌IP打造。
应用场景
短视频创作 快速生成抖音/小红书/TikTok 竖屏视频(9:16),日更无忧
社交媒体营销 制作品牌活动预告、节日贺片,保持视觉统一性
电商产品展示 自动生成360°商品动画、使用场景演示,提升转化率
影视预可视化 快速产出分镜预览、氛围测试视频,加速前期决策
广告创意制作 一键生成病毒式短片、品牌广告,支持多种艺术风格
教育培训 制作历史场景还原、科学原理动画、语言对话视频,提升教学沉浸感
Seedance vs Seedream:AI 内容创作双引擎
Seedance 2.0(视频)
Seedream 5.0(图像)
定位 电影级 AI 视频生成 专业级 AI 图像生成
核心能力 音画同步、多镜头、长视频 文生图、参考生图、高清编辑
一句话总结 “从0到1做完整短片” “做图、修图、做素材”
协同关系 可直接调用 Seedream 生成的图像作为参考帧,无缝衔接创作流程












